Coordinated Response
Services and tools for incident response management
Highlights
Dell SecureWorks Ten Tips to Control a Security Breach
Dell SecureWorks – 10 Tips to Help You Minimize the Duration and Impact of a Security Breach.
The message from Dell SecureWorks re-enforces the message from other security resources, but the presentation available on BitPipe provides additional insight. The tips start and end with Incident Response.
1) Have a computer Security Incident Response plan in place before you need it.
The plan includes roles, responsibilities, and stakeholders; addresses compliance with key industry mandates; and addresses key attacks that may disrupt business.
2) Assess current Incident Response competencies.
Identify gaps and take pro-active steps to enhance capabilities.
3) Get full management and executive leadership buy-in on the Incident Response Plan.
Incident Response should reflect information security risk assessments and this should be an extension of the corporate risk assessment.
4) thru 9) Tips Representing Security Best Practices
The additional tips include cybersecurity best practices: (4) assess user privileges and accounts; (5) collect and analyze log data; (6) control traffic flows; (7) monitor network activity; (8) perform filtering for web and email; and (9) monitor DNS activity.
10) Apply threat intelligence to enhance Incident Response.
Attackers rarely limit their targets. This is an important step in raising preparedness.
Coordinated Response
Coordinated Response can help (1) develop an Incident Response Plan, (2) perform an incident response capabilities assessment, and (3) develop the risk assessment to support executive buy-in. Please contact us if we can be of help.
CSO’s Five Tips for Effective Incident Response
“CSO talked to industry experts at Black Hat about the ups and downs of Incident Response, and how to develop a plan that’s right for you.”
Steve Ragan, reporting from the Black Hat Conference, published this good article in CSO Online:
Understanding incident response: 5 tips to make IR work for you.
“Incident response is a plan that evolves over time to keep your organization best prepared against likely threats.” The article is worth reading. The reflections and quotes provide the real insight, but the five tips drive home the message.
Know your data.
Understand the types of data on your network, where it lives, and its value. Map all the ways this data can be accessed.
Document plans for various scenarios.
Not every incident is about a hacker. Plan for internal events, as well. Address incidents stemming from lost or stolen assets and malicious actors from within (including when an outsider compromises an insider’s access).
Establish a base of operations.
A command center of sorts, even a conference room, makes it easier to coordinate the incident response activity.
Nominate a single point of contact.
Make sure they have access to the right individuals. Know when to involve Public Relations and Legal. This is what Coordinated Response calls the extended response.
Update and maintain your plan.
Keep information current. Reflect changes to the network, to the data, to the workforce. This should be done at least yearly.
Related Articles
Coordinated Response
Coordinated Response can help map your data and your value chain in to a meaningful risk/impact assessment model. We can help you develop or refresh your existing plan. We can help build out your plan for various scenarios. If you are interested, please contact us.
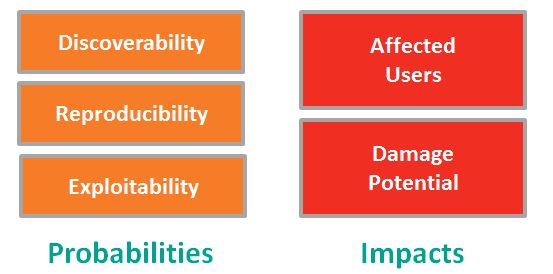
Threat and Impact Assessment with DREAD
DREAD – Damage Potential, Reproducibility, Exploitability, Affected Users, and Discoverability – is used to quantify risk, but it may prove useful for incident impact assessment.
DREAD is a classification scheme for quantifying, comparing, and prioritizing the amount of risk represented by a specific threat. The DREAD scheme is described in Writing Secure Code, 2nd Edition, Howard, M. and LeBlanc, D. Microsoft Press 2003 and is used by Microsoft. DREAD is also promoted by the Open Web Application Security Project (OWASP) on their site: Threat Risk Modeling.
In the diagram above and in the definitions below, the “D”s are reordered to group the elements of DREAD into logical categories: Probabilities and Impacts.
Threat Probabilities:
How easy is it to (1) Discover a vulnerability, (2) Exploit a vulnerability, and (3) Reproduce the Exploit? In DREAD these are rated on a scale of 0 (very hard or impossible) to 10 (easy with limited tools or skills).
Threat Impacts:
Affected Users are measured from 0 (none) to 5 (Some users, but not all) to 10 (all users). Damage Potential is measured from 0 (no damage from exploit) to 5 (individual user data is compromised) or 10 (complete system or data destruction or compromise).
Risk Measure:
Add the 5 metrics and divide by 5. The result is a scale of 0 (not likely with limited impact) to 10 (highly likely with serious impact). Obviously, higher risk requires additional mitigation or avoidance might be required.
Incident Response and Risk Assessment
It’s worth stressing that the impact component of the risk assessment can and should be used during the Incident Impact Assessment. The Response Team needs to know how many users are affected, how much data or how many systems have been compromised, destroyed or disabled.
With this information the response team makes informed decisions on what resources to apply and what actions to take.
In an Incident postmortem review, the questions about the vulnerability should be reviewed: discoverability, reproducibility, and exploitability (again).
Forrester 7 steps to building an effective incident response program
Forrester Senior Analyst Rick Holland identifies the keys to an effective incident response program.
This article, available through TechTarget, is a good tool for communicating with your executive team.
The article references an interesting point. According to the Forrester Forrsights Security Survey, after a breach has occurred, 25% of organizations increase spending on breach prevention technologies, while 23% increase spending on the incident response program itself.
(1) Be self-aware.
Know your capabilities and constraints. Avoid overestimating your abilities. An outside perspective may provide clarity.
(2) Technology – understand its benefits and limitations.
Technology spending outweighs investments in incident response programs, but technology does not equal a solution.
(3) Establish realistic reporting metrics.
Time-to-detect, time-to-contain, and time-to-re-mediate are good results-oriented metrics. Think of others. Consider trending and its implications.
(4) Make the program scalable.
Larger organizations have larger challenges addressing incident response. Consider a contingency team as well as internal and external specialists.
(5) Collaborate internally and externally.
Incident response teams should not work in isolation. Involve your vendors and suppliers.
(6) Engage executives.
Align security programs, including incident response, with the business value chain. Connecting the response plan to an enterprise risk assessment is key.
(7) Operate with autonomy.
To avoid micro-management, establish rules of engagement that identify the need for approval balanced against the need to act.
Coordinated Response
This article provides a good set of principles to apply as you build or enhance your incident response program.
Let us help you with a response plan review that applies and expands on the ideas presented by Forrester.
NIST Incident Impact Assessment – Revised
NIST Revised their guidance on Incident Impact Assessment in The Computer Security Incident Handling Guide, SP 800-61 Revision 2, August 2012.
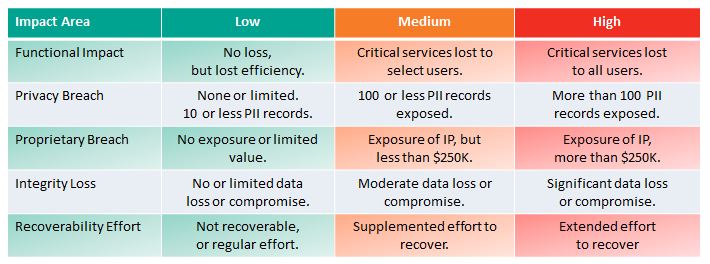
Revision 1 provided a complex measure for incident impact assessment that might provide insight in hindsight, but one that was not practical, applicable, or useful in the midst of an incident response. The new measures, suggested in the table above, are really quite useful, applicable, and discernible. There are 3 important impact areas with associated metrics:
- Functional impact
- Information Impact
- Recoverability Effort
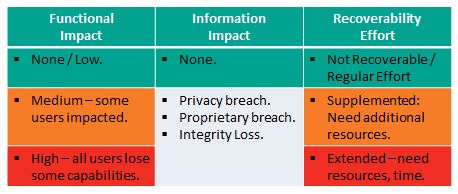
Functional Impact
This measures loss of system functionality. NONE – No loss of functionality. LOW – no loss of functionality, but loss of efficiency. MEDIUM – Critical services lost to a subset of users. HIGH – Critical services lost to all users.
Information Impact
Here NIST stops short of measuring impact – so the above diagram is not colored for this Impact Area except in the case of NONE – no information was exfiltrated, modified, or deleted. An impact measure is needed for each of the three information impact areas. PRIVACY BREACH – personally identifiable information was compromised. PROPRIETARY BREACH – unclassified proprietary data was compromised. INTEGRITY LOSS – sensitive or proprietary information was changed or deleted. A level of impact measure is needed in each of these areas. The loss of a single document or individual’s data is low, but what defines medium or high?
Recover-ability Effort
This is an interesting and useful metric: Is the data/system recoverable? If so, what is the level of recovery effort? NOT RECOVERABLE – the data or system cannot be recovered. REGULAR – time-to-recover is predicable with existing resources. SUPPLEMENTED – time-to-recover is predictable, but with additional resources. EXTENDED – time-to-recover is unpredictable and additional resources including outside help are needed.
Coordinated Response
This new approach agrees with the Coordinated Response Impact Assessment in the Response Management Framework. The table below shows the 5 possible impact areas with associated impact metrics.
Coordinated Response can help you review and improve your Incident Response Plan.

Incident Response – 3 Big Mistakes
Dark Readings identifies 3 Big Mistakes in Incident Response, May 13, 2013.
By recognizing and avoiding these common mistakes, Kelly Jackson Higgins provides a quick set of best practices backed by interviews with security experts. The article should be in every Response Teams must-read library. A response plan should identify the practices to avoid these mistakes:
- Assuming It’s an APT; don’t confuse expectations with facts.
- Not Monitoring Traffic; beyond detection, supports investigation.
- Focusing Only on the Malware; eradication is important, but so investigation.
Assuming It’s an APT
Not all attacks start with an Advanced Persistent Threat. Apply an objective lens to the data. Look for a 2 stage attack: (1) Phishing, (2) Command and Control.
Not Monitoring Traffic
The article makes a good point. Monitoring is not just for protection and detection. When a breach or intrusion is discovered, audit records provide clues as to what happened, when, and what may be ex-filtrated. Not monitoring, even insufficient monitoring increases potential impact.
Focusing Only on the Malware
Containment and eradication are important, but determining outcomes – data theft, sabotage, other long-term damage – may be more important.
Avoid Tunnel Vision
This was not called out as a 4th mistake, but the article led with an example of a team that was focused on the malware and missed a shift to control of an administrative tool. The admonition to “avoid tunnel vision” applies more broadly than just “focusing on malware”.
The example also identified a good practice. An outside firm reviewed the outcome of the incident and discovered the control shift – the true intent of the attack.
Coordinated Response
Coordinated Response can help to broaden your view and t0 improve your incident response plan.

Risk Assessment and Incident Response
Align your Incident Response plan with your information security risk assessment.
An effective risk assessment, regardless of the technique employed, identifies impact areas and potential impact levels. Then, given the probabilities an attack, risk strategies are defined: avoid the risk; mitigate the risk; share the risk; accept remaining risk.
Ultimately, unless you choose to avoid the risk, some residual risk is accepted. Then, when an unlikely incident occurs, an incident response plan is the last line of defense.
Risk Assessment – Incident Response – Impact Assessment
The key to an effective impact assessment rests with two key questions:
• What areas of your business are at risk when an incident occurs?
• How do you measure the impact?
These two questions are first asked during the risk assessment – the theoretical question: what if? When an incident occurs, they are asked again, only it is no longer in theory. What areas of your business are affected? To what level?
Impact Areas
While most organizations evaluate the financial impact, the majority view reputational impact as the more important. Other areas to measure include operational impact and legal impact. If your organization is regulated, you might measure legal impact, policy impact, and regulatory impact as separate areas.
Impact Levels
For each impact area, it is important to provide metrics or descriptions that differentiate the impact level. Low, medium, and high are not enough as impact measures. Without metrics different people assign different meanings to the terms low, medium, and high.
An Incident Response Plan Review
It’s worth stressing that the impact component of the risk assessment can and should be used during the Incident Impact Assessment. The Response Team measures adverse impact to determine the needed response.
With this information the response team makes informed decisions on what resources to apply and what actions to take. Refer to our Response Management Framework for added insight.
Let us help you with a response plan review that considers your information security risk assessment.
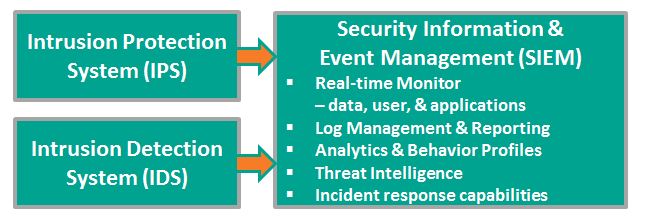
Does SIEM Meet Your Incident Response Needs?
Security Information & Event Management (SIEM) systems provide real-time monitoring and advanced analytics and generate automatic alerts for potentially adverse events.
Most SIEM vendors from HP and IBM to LogRythm and LogLogics offer tools that support incident response, but in the words of one research organization the response is IT-focused and tightly coupled to the SIEM. The enterprise is not involved. Artifacts are limited to SIEM records. Incidents derived from outside the SIEM – help desk tickets, third party alerts, etc. – are not tracked at all.
There is a need to manage incidents at an enterprise-level. In addition to IT, there is involvement and support from:
- Risk Management Operations
- Corporate Counsel and outside legal counsel
- Public Affairs, Public Relations, and/or Media Relations
- Executive Leaderships
- Security Operations – Physical Security and Facilities Management
- Third party experts – IT, Forensics, Cybersecurity, Legal, etc.
SIEM vendors provide no interface supporting these enterprise actors. The researchers suggest connecting with an enterprise process automation platform, for example, Microsoft (TM) SharePoint, a platform that provides:
- Content and records management for Incident Documentation and Evidence
- Process automation with Alerts, Notifications, Approvals, and Assignments
- Change management records and audit trails
Coordinated Response embraces the SIEM response capability, but extends it to the Enterprise level.
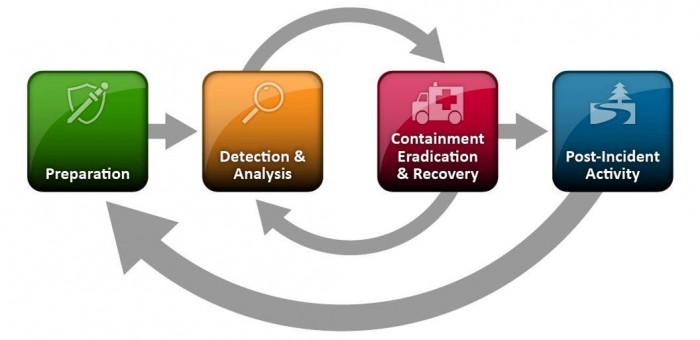
What Else Does NIST Say?
The National Institute of Standards and Technology (NIST) released The Computer Security Incident Handling Guide, SP 800-61 Revision 2, in August, 2012.
The guide puts incident handling activities in the context of the above diagram. The table below provides the first level of detail.
| Preparation | Detection & Analysis | Containment, Eradication, & Recovery | Post-Incident Activity |
|---|---|---|---|
|
|
|
|
The above activities represent a useful checklist for evaluating an incident response plan as well as incident handling in action.
Of course, recognize that the response to an incident is fluid, often with unclear boundaries. Containment may start in the early stages of analysis. Prioritization may change and notification may continue throughout the incident. But, the insight provided by the NIST publication goes beyond Federal agencies.
Federated Cybersecurity: A Hybrid Approach to Safety
I attended the CSO Perspectives event in Alexandria, Virginia on March 21st. This event was produced by CSO Magazine and CSO Online. Publisher Bob Bragdon was the host and moderator. During the course of the day, there was an extensive discussion of the Federal Government’s role in Cybersecurity.
Over lunch, with Bob and a number of others, I suggested we need a federated approach to cybersecurity.
Consider highway safety for a moment and all the factors that make it safe to drive:
- Highways are built to a standard of safety. Interstate highways meet Federal standards. The standard defines safe lane widths, median strips, shoulders, guard rails when necessary, on and off ramps and more.
- State and local laws dictate speed limits.
- State and local police enforce the laws.
- Federal regulations direct automotive manufacturers to build safe cars with seat belts and air bags, signal lights, brake lights, and more.
- Automotive manufacturers add crash zones and other details competing for the moniker of safest.
- You and I are required to get a driver’s license by passing a written test and a driving test (though I confess it’s been a few decades since I last took the test).
- Young drivers need to meet a higher standards in most states to get their drivers permit.
- Our insurance companies encourage us to drive safely with threat of higher premiums when we don’t.
- Of course, there are incident response services: from emergency response to AAA.
This federated approach to safety and security is needed on the information highway (now there is a dated term). We expect hardware and software manufacturers to build safer products. But, we need to be trained to use them properly and not to turn off safety features or, in some cases, we need to be trained to turn them on. The network service providers and internet service providers need to build safer “highways”. We still need government regulations and enforcement.
How do we protect against malicious drivers? This is a metaphor worth exploring.
About Us
Learn More
Latest Highlights

Contact Us